Der Mensch, den Sie hier sehen ...existiert nicht! Wie ist das möglich? Das Foto wird bei jedem Seitenaufruf neu durch eine künstliche Intelligenz (KI/AI) generiert. probieren Sie es aus: 🔄
Die angezeigte Person ist 100%ig synthetisch und rein fiktiv bei einer gleichzeitigen Qualität an Authentizität, die uns nicht mehr erlaubt zu unterscheiden, ob echt oder unecht. Wie das technisch möglich ist, erklärt Ihnen der untenstehende Artikel. Sie dürfen diese Fotos frei verwenden, für was auch immer, denn wer nicht existiert, hat keine Rechte am eigenen Bild. Verrückt, oder? Hier sehen Sie die Zukunft in der Werbe- und Modellindustrie schon heute. Aber was können wir noch glauben, wenn wir nicht mal mehr sicher sein können, ob die Menschen, die wir sehen real sind? “Ich versuche deinen Verstand zu befreien, Neo. Aber ich kann dir nur die Tür zeigen. Hindurchgehen musst du alleine. [...] Wenn real bedeutet zu fühlen, riechen, tasten und sehen, dann ist ‘real’ nichts anderes als elektrische Signale, von deinem Gehirn zur Schau gestellt.” - Matrix, Film
Stilbasierte GANs - Generieren und Optimieren realistischer künstlicher Gesichter
Generative Adversarial Networks (GAN) sind ein relativ neues Konzept des maschinellen Lernens, das 2014 erstmals eingeführt wurde. Ihr Ziel ist es, künstliche Proben wie Bilder zu synthetisieren, die sich nicht von authentischen Bildern unterscheiden. Ein häufiges Beispiel für eine GAN-Anwendung ist das Erzeugen künstlicher Gesichtsbilder durch Lernen aus einem Datensatz von Promi-Gesichtern. Während GAN-Bilder im Laufe der Zeit realistischer wurden, besteht eine ihrer größten Herausforderungen darin, ihre Ausgabe zu steuern, dh bestimmte Merkmale wie Pose, Gesichtsform und Frisur in einem Gesichtsbild zu ändern.
In einem neuen Artikel von NVIDIA, einer stilbasierten Generatorarchitektur für GANs ( StyleGAN ), wird ein neues Modell vorgestellt, das dieser Herausforderung begegnet . StyleGAN generiert das künstliche Bild schrittweise, beginnend mit einer sehr niedrigen Auflösung bis hin zu einer hohen Auflösung (1024 × 1024). Indem Sie die Eingabe für jede Ebene separat ändern, steuern Sie die visuellen Merkmale, die in dieser Ebene ausgedrückt werden, von groben Merkmalen (Pose, Gesichtsform) bis hin zu feinen Details (Haarfarbe), ohne andere Ebenen zu beeinträchtigen.
Diese Technik ermöglicht nicht nur ein besseres Verständnis der erzeugten Ausgabe, Es liefert aber auch hochmoderne Ergebnisse - hochauflösende Bilder, die authentischer aussehen als zuvor erzeugte Bilder.
Hintergrund
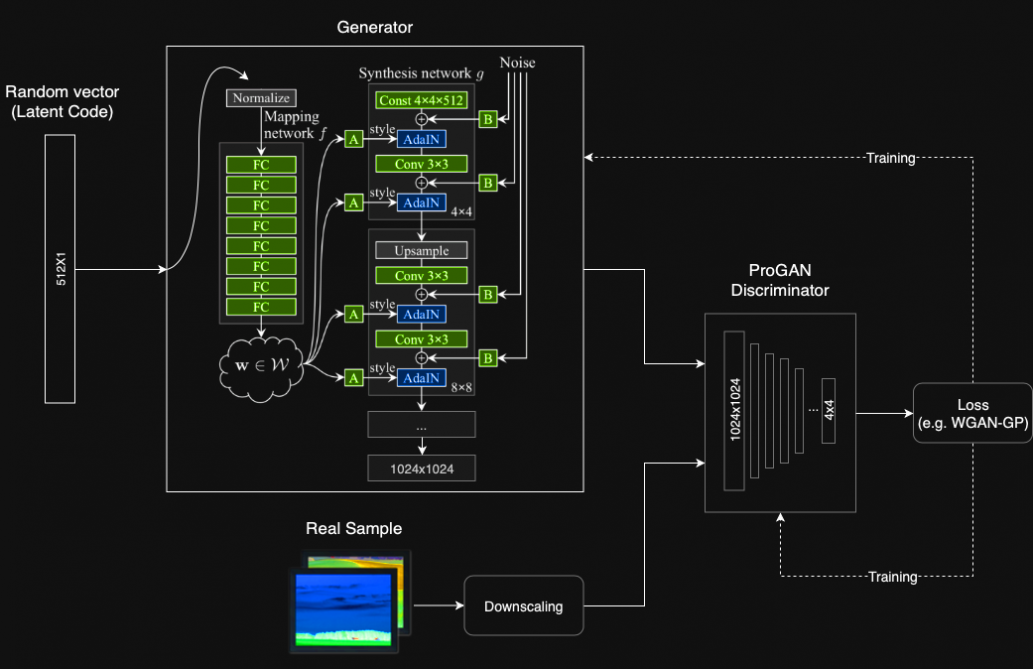
Die Grundkomponenten jeder GAN sind zwei neuronale Netze - ein Generator, der neue Samples von Grund auf neu synthetisiert, und ein Diskriminator, der Samples sowohl aus den Trainingsdaten als auch aus dem Generatorausgang entnimmt und vorhersagt, ob sie "echt" oder "falsch" sind.
Der Generatoreingang ist ein Zufallsvektor (Rauschen) und daher ist sein anfänglicher Ausgang auch Rauschen. Mit der Zeit lernt es, wenn es Feedback vom Diskriminator erhält, "realistischere" Bilder zu synthetisieren. Der Diskriminator verbessert sich auch mit der Zeit, indem er erzeugte Abtastwerte mit realen Abtastwerten vergleicht, was es für den Generator schwieriger macht, sie zu täuschen.
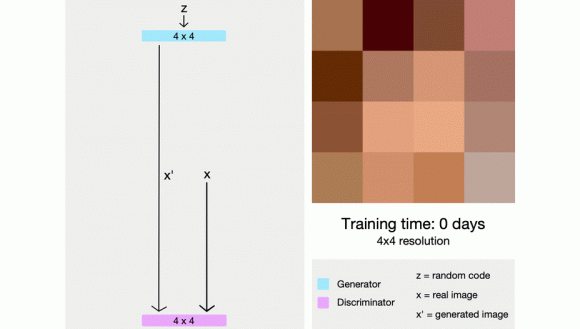
GANs Übersicht
Bis 2018, als NVIDIA die Herausforderung erstmals mit ProGAN anpackte, hatten die Forscher Probleme, qualitativ hochwertige Großbilder (z. B. 1024 × 1024) zu erstellen . Die Hauptinnovation von ProGAN ist das progressive Training - es beginnt mit dem Training des Generators und des Diskriminators mit einem Bild mit sehr niedriger Auflösung (z. B. 4 × 4) und fügt jedes Mal eine Schicht mit höherer Auflösung hinzu.
Diese Technik schafft zunächst die Grundlage des Bildes, indem die Basismerkmale erlernt werden, die auch bei niedriger Auflösung auftreten Bild, und lernt mit der Zeit immer mehr Details, je höher die Auflösung ist. Das Training der Bilder mit niedriger Auflösung ist nicht nur einfacher und schneller , Es hilft auch beim Trainieren der höheren Ebenen, und als Ergebnis ist das Gesamttraining auch schneller.
ProGAN-Übersicht
ProGAN erzeugt qualitativ hochwertige Bilder, aber wie bei den meisten Modellen ist seine Fähigkeit, bestimmte Merkmale des erzeugten Bildes zu steuern, sehr begrenzt. Mit anderen Worten, die Features sind verwickelt und der Versuch, die Eingabe auch nur geringfügig zu optimieren, wirkt sich normalerweise auf mehrere Features gleichzeitig aus. Eine gute Analogie dafür wären Gene, bei denen die Veränderung eines einzelnen Gens mehrere Merkmale beeinflussen könnte.
ProGAN progressives Training von niedrig bis hoch auflösenden Schichten. Quelle: (Sarah Wolfs großartiger Blogbeitrag auf ProGAN).
So funktioniert StyleGAN
Das StyleGAN-Paper bietet eine aktualisierte Version des ProGAN-Image-Generators mit Schwerpunkt auf dem Generator-Netzwerk. Die Autoren stellen fest, dass ein potenzieller Vorteil der ProGAN - Progressivschichten darin besteht, dass sie verschiedene visuelle Merkmale des ProGAN steuern können Bild, bei sachgemäßer Verwendung. Je niedriger die Ebene (und die Auflösung), desto gröber sind die davon betroffenen Features. Das Papier unterteilt die Merkmale in drei Typen:
Grob - Auflösung von bis zu 8 2 - wirkt sich auf Pose, allgemeine Frisur, Gesichtsform usw. Aus
Mittlere Auflösung von 16 2 bis 32 2 - wirkt sich auf feinere Gesichtszüge, Frisur, offene / geschlossene Augen usw. aus.
Die Feinauflösung von 64 2 bis 1024 2 wirkt sich auf das Farbschema (Augen, Haare und Haut) und die Mikromerkmale aus.
Der neue Generator enthält mehrere Ergänzungen zu den Generatoren des ProGAN:
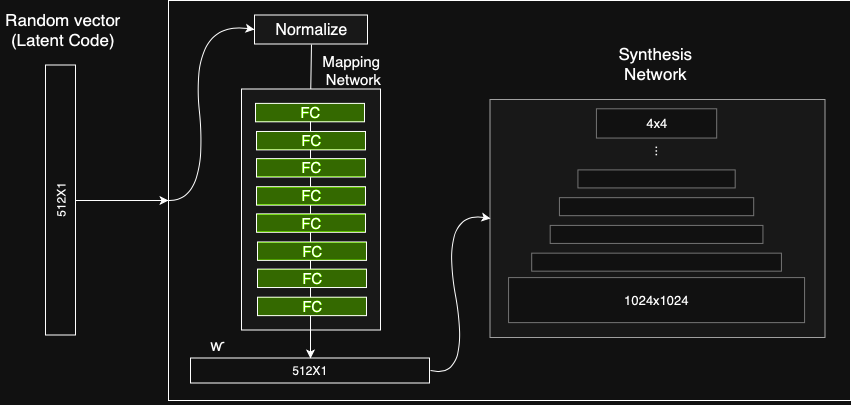
Mapping-Netzwerk
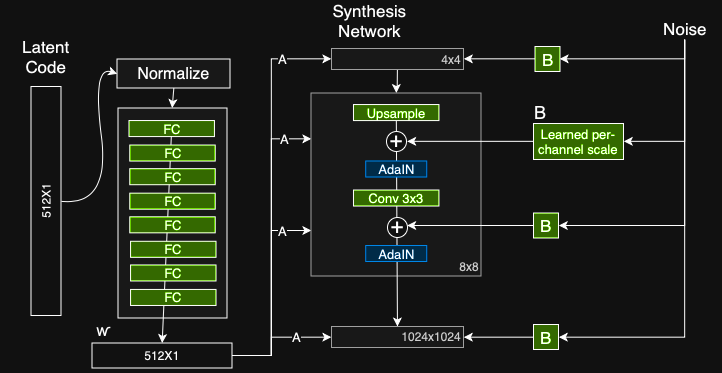
Das Ziel des Mapping-Netzwerks besteht darin, den Eingabevektor in einen Zwischenvektor zu codieren, dessen verschiedene Elemente verschiedene visuelle Merkmale steuern. Dies ist kein trivialer Vorgang, da die Möglichkeit zur Steuerung visueller Merkmale mit dem Eingabevektor begrenzt ist, da diese der Wahrscheinlichkeitsdichte der Trainingsdaten folgen müssen. Wenn beispielsweise Bilder von Personen mit schwarzen Haaren häufiger im Dataset vorkommen, werden diesem Feature mehr Eingabewerte zugeordnet. Infolgedessen ist das Modell nicht in der Lage, Teile der Eingabe (Elemente im Vektor) auf Features abzubilden, ein Phänomen, das als Feature-Verschränkung bezeichnet wird. Durch die Verwendung eines anderen neuronalen Netzwerks kann das Modell jedoch einen Vektor generieren, der der Verteilung der Trainingsdaten nicht folgen muss, und die Korrelation zwischen Merkmalen verringern. Das Mapping-Netzwerk besteht aus 8 vollständig verbundenen Layern, und sein Ausgang w hat die gleiche Größe wie der Eingang (512 × 1).
Der Generator mit dem Mapping-Netzwerk (zusätzlich zum ProGAN-Synthese-Netzwerk)
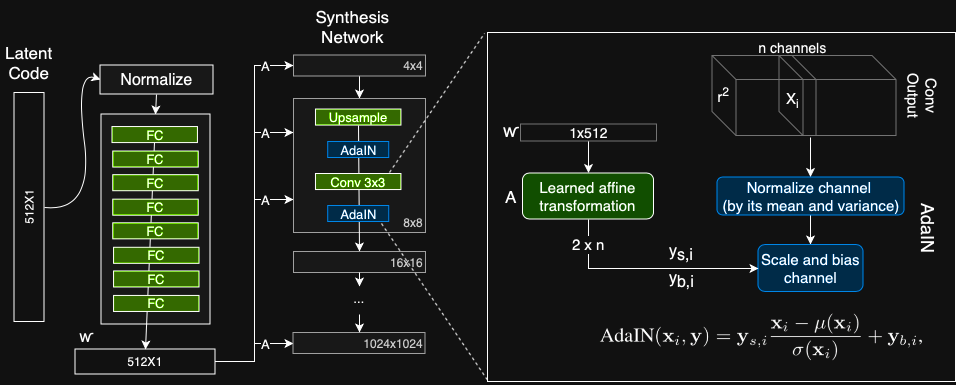
Stilmodule (AdaIN)
Das AdaIN-Modul (Adaptive Instance Normalization) überträgt die vom Mapping-Netzwerk erstellten codierten Informationen in das generierte Bild. Das Modul wird zu jeder Auflösungsstufe des Synthesis-Netzwerks hinzugefügt und definiert den visuellen Ausdruck der Funktionen in dieser Stufe:
Jeder Kanal der Faltungsschichtausgabe wird zuerst normalisiert, um sicherzustellen, dass die Skalierung und Verschiebung von Schritt 3 den erwarteten Effekt haben.
Der Zwischenvektor w wird unter Verwendung einer anderen vollständig verbundenen Schicht (markiert als A) in eine Skala und Vorspannung für jeden Kanal transformiert.
Die Skalierungs- und Vorspannungsvektoren verschieben jeden Kanal des Faltungsausgangs, wodurch die Wichtigkeit jedes Filters in der Faltung definiert wird. Diese Abstimmung übersetzt die Informationen von w in eine visuelle Darstellung.
Die adaptive Instanznormalisierung des Generators (AdaIN)
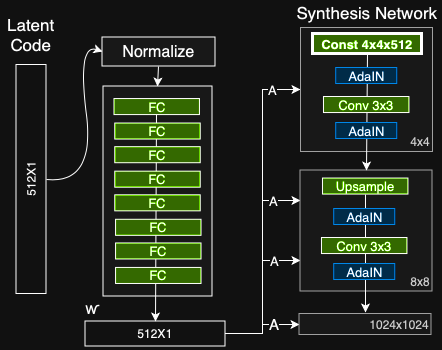
Traditionelle Eingabe entfernen
Die meisten Modelle und ProGAN unter Sie, Verwenden Sie die Zufallseingabe, um das Ausgangsbild des Generators zu erstellen (dh die Eingabe des 4 × 4-Pegels). Das StyleGAN-Team stellte fest, dass die Bildfunktionen von w und AdaIN gesteuert werden. Daher kann die anfängliche Eingabe weggelassen und durch konstante Werte ersetzt werden. Obwohl das Papier nicht erklärt, warum es die Leistung verbessert, besteht eine sichere Annahme darin, dass es die Funktionsverschränkung verringert - es ist für das Netzwerk einfacher, nur mit w zu lernen, ohne sich auf den verschränkten Eingabevektor zu verlassen.
Der Synthesis Network-Eingang wird durch einen konstanten Eingang ersetzt
Stochastische Variation
Es gibt viele Aspekte in den Gesichtern der Menschen, die klein sind und als stochastisch angesehen werden können, wie Sommersprossen, genau Platzierung der Haare, Falten, Merkmale, die das Bild realistischer machen und die Vielfalt der Ergebnisse erhöhen. Die übliche Methode zum Einfügen dieser kleinen Merkmale in GAN-Bilder besteht darin, dem Eingabevektor zufälliges Rauschen hinzuzufügen. In vielen Fällen jedoch Fälle Es ist schwierig, den Rauscheffekt zu steuern, da das oben beschriebene Phänomen der Verschränkung von Merkmalen dazu führt, dass andere Merkmale des Bildes beeinträchtigt werden.
Das Rauschen in StyleGAN wird auf ähnliche Weise wie beim AdaIN-Mechanismus hinzugefügt. - Jedem Kanal wird vor dem AdaIN-Modul ein skaliertes Rauschen hinzugefügt, das den visuellen Ausdruck der Funktionen der Auflösungsstufe, mit der es arbeitet, ein wenig ändert.
Hinzufügen von skaliertem Rauschen zu jeder Auflösungsstufe des Synthesenetzwerks
Style mischen
Der StyleGAN-Generator verwendet den Zwischenvektor in jeder Ebene des Synthesenetzwerks, wodurch das Netzwerk möglicherweise erfährt, dass Ebenen korreliert sind. Um die Korrelation zu verringern, wählt das Modell zufällig zwei Eingangsvektoren aus und erzeugt für sie den Zwischenvektor w. Anschließend werden einige der Ebenen mit der ersten trainiert und (an einem zufälligen Punkt) auf die andere umgeschaltet, um den Rest der Ebenen zu trainieren. Der Zufallsschalter stellt sicher, dass das Netzwerk nicht lernt und sich auf eine Korrelation zwischen Ebenen verlässt.
Dieses Konzept verbessert zwar nicht bei allen Datensätzen die Modellleistung, hat jedoch einen sehr interessanten Nebeneffekt: Es kann mehrere Bilder auf kohärente Weise kombinieren (siehe Video unten). Das Modell generiert zwei Bilder A und B und kombiniert sie dann, indem es Features auf niedriger Ebene aus A und die restlichen Features aus B entnimmt.
Trunkierungstrick in W
Eine der Herausforderungen bei generativen Modellen besteht darin, Bereiche zu behandeln, die in den Trainingsdaten schlecht dargestellt sind. Der Generator kann sie nicht lernen und erstellt Bilder, die ihnen ähneln (und erstellt stattdessen schlecht aussehende Bilder). Um zu vermeiden, dass schlechte Bilder erzeugt werden, schneidet StyleGAN den Zwischenvektor w ab und zwingt ihn dazu bleibe in der Nähe des "durchschnittlichen" Zwischenvektors.
Nach dem Trainieren des Modells wird durch Auswahl vieler zufälliger Eingaben ein Durchschnittswert erzeugt. Erzeugen ihrer Zwischenvektoren mit dem Mapping-Netzwerk; und Berechnen des Mittelwerts dieser Vektoren. Beim Generieren neuer Bilder wird w anstelle der direkten Verwendung der Mapping-Netzwerk-Ausgabe in w new = w avg + 𝞧 (w - w avg ) transformiert, wobei der Wert von 𝞧 definiert, wie weit das Bild vom „Durchschnittsbild“ entfernt sein kann ( und wie vielfältig die Ausgabe sein kann). Interessanterweise kann das Modell durch die Verwendung eines anderen 𝞧 für jede Ebene vor dem affinen Transformationsblock steuern, wie weit die einzelnen Features vom Durchschnitt entfernt sind, wie im folgenden Video gezeigt.
Optimieren Sie das generierte Bild, indem Sie den Wert von 𝞧 in verschiedenen Stufen ändern
Feintuning
Eine zusätzliche Verbesserung von StyleGAN gegenüber ProGAN bestand in der Aktualisierung mehrerer Netzwerk-Hyperparameter wie Trainingsdauer und Verlustfunktion sowie im Ersetzen der Aufwärts- / Abwärtsskalierung vom nächsten Nachbarn zur bilinearen Abtastung. Obwohl dieser Schritt für die Modellleistung von Bedeutung ist, ist er weniger innovativ und wird daher hier nicht im Detail beschrieben (Anhang C im Artikel).
Ein Überblick über StyleGAN
Ergebnisse
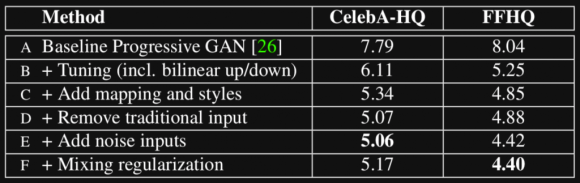
Der Artikel präsentiert die neuesten Ergebnisse zu zwei Datensätzen - CelebA-HQ, der aus Bildern von Prominenten besteht, und einem neuen Datensatz Flickr-Faces-HQ (FFHQ), der aus Bildern von „normalen“ Personen besteht und ist abwechslungsreicher. Die folgende Tabelle zeigt die Frèchet Inception Distance ( FID ) -Werte verschiedener Konfigurationen des Modells.
Die Leistung (FID-Score) des Modells in verschiedenen Konfigurationen im Vergleich zu ProGAN. Je niedriger die Punktzahl, desto besser das Modell (Quelle: StyleGAN )
Zusätzlich zu diesen Ergebnissen zeigt das Papier, dass das Modell nicht nur auf Gesichter zugeschnitten ist, indem seine Ergebnisse auf zwei weiteren Datensätzen von Schlafzimmerbildern und Autobildern dargestellt werden.
Feature-Entflechtung
Um die Diskussion über die Merkmalstrennung quantitativer zu gestalten, werden zwei neue Methoden zur Messung der Merkmalentflechtung vorgestellt:
Perzeptive Pfadlänge - Messen Sie den Unterschied zwischen aufeinanderfolgenden Bildern (deren VGG16-Einbettungen), wenn Sie zwischen zwei zufälligen Eingaben interpolieren. Drastische Änderungen haben zur Folge, dass sich mehrere Features gemeinsam geändert haben und möglicherweise ineinander verwickelt sind.
Lineare Trennbarkeit - die Fähigkeit, Eingaben in Binärklassen wie männlich und weiblich zu klassifizieren. Je besser die Klassifizierung ist, desto trennbarer sind die Merkmale.
Durch den Vergleich dieser Metriken für den Eingabevektor z und den Zwischenvektor w zeigen die Autoren, dass Merkmale in w signifikant besser trennbar sind. Diese Metriken zeigen auch den Vorteil der Auswahl von 8 Layern im Mapping-Netzwerk im Vergleich zu 1 oder 2 Layern.
Fazit
StyleGAN ist ein bahnbrechendes Papier, das nicht nur qualitativ hochwertige und realistische Bilder erzeugt, sondern auch eine hervorragende Kontrolle und ein besseres Verständnis der erzeugten Bilder ermöglicht, wodurch es noch einfacher als zuvor ist, glaubwürdige gefälschte Bilder zu erzeugen. Die in StyleGAN vorgestellten Techniken, insbesondere das Mapping-Netzwerk und die adaptive Normalisierung (AdaIN), werden wahrscheinlich die Grundlage für viele zukünftige Innovationen in GANs sein.

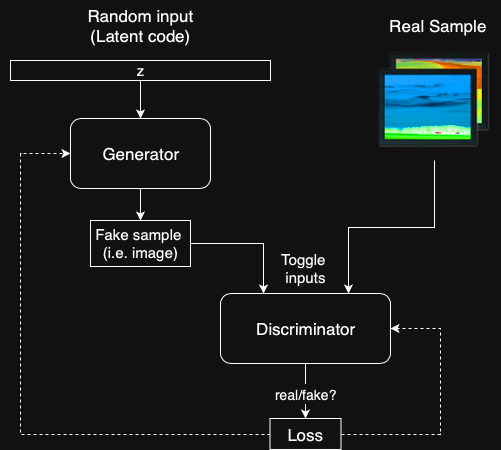 Zeit lernt es, wenn es Feedback vom Diskriminator erhält, "realistischere" Bilder zu synthetisieren. Der Diskriminator verbessert sich auch mit der Zeit, indem er erzeugte Abtastwerte mit realen Abtastwerten vergleicht, was es für den Generator schwieriger macht, sie zu täuschen.
Zeit lernt es, wenn es Feedback vom Diskriminator erhält, "realistischere" Bilder zu synthetisieren. Der Diskriminator verbessert sich auch mit der Zeit, indem er erzeugte Abtastwerte mit realen Abtastwerten vergleicht, was es für den Generator schwieriger macht, sie zu täuschen.